1. Faster R-CNN 概述
Faster R-CNN[1] 是典型的两阶段的目标检测算法,两阶段的目标检测算法由 R-CNN 到 Fast R-CNN,再发展到 Faster R-CNN,其最主要的发展脉络是如何加速模型的检测速度:
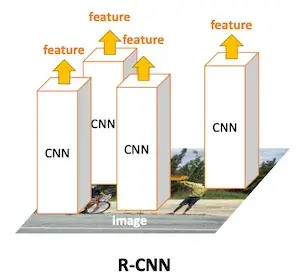
- R-CNN:由启发式的方法,如 Selective Search 等方法在原图上找到候选,每一个候选框经过 CNN 网络得到每一个候选框对应的语义向量,再通过 SVM 分类器判别是否是需要的候选框,并训练一个边界框回归模型,对最终的边界框优化。可以发现在整个过程中被割裂成了多个独立的部分,其过程如下图所示[2]:
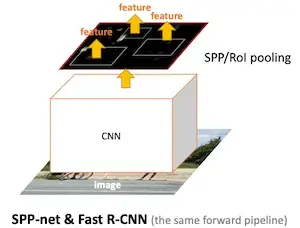
- Fast R-CNN:通过 R-CNN,发现每个候选框都要经过 CNN 网络提取语义向量,通过最后还得经过 SVM 和边界框回归得到最终的判断和边界框,这里完全可以在一个网络里实现,因此在 Fast R-CNN 中只需要将原图通过一次 CNN 网络,并将候选框映射到特征图上,得到对应的语义向量,这很大程度上提高了检测的速度,同时,通过一个网络实现目标的判断以及边界框的回归,也使得整个过程不再是孤立的,其过程如下图所示[2]:
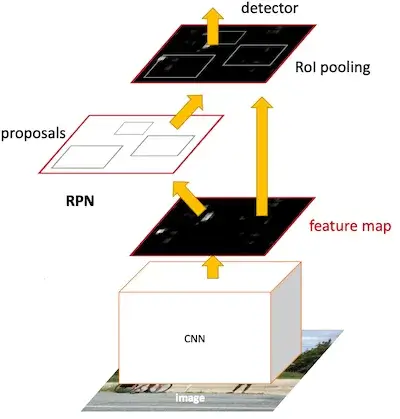
- Faster R-CNN:Fast R-CNN 的进一步优化,这次是对候选框的选择部分,在 Fast R-CNN 及之前的模型中是使用启发式的方法预先选择出一部分的候选框,在 Faster R-CNN 直接使用 CNN 网络代替这部分,其过程如下图所示[2]:
2. Finetune Faster R-CNN
在 PyTorch 的 TorchVision 包中提供了多种 backbone 的 Faster R-CNN 实现,对于一个新的目标检测任务,我们需要 Finetune 这些模型,以适应新的任务,Finetune 的过程大致需要以下几个步骤:
- 构造数据集
- 搭建模型
- 损失函数
- 模型训练
- 模型预测
2.1. 构造数据集
在此,我们选择 Kaggle 上的一个口罩检测的数据集[3],数据集分为两个文件夹:
images:包含了原始的图片annotations:包含了图片的标注结果,格式为xml格式
我们以其中一张图为例,展示原图以及标注后的结果:

其中,绿色的框表示戴了口罩,红色的框表示未戴口罩。为了方便后面的数据集的准备,我们先对数据进行一次处理,将标注结果全部从 xml 文件中读取出来:
import os
import xml.etree.ElementTree as ET
annotation_file_list = os.listdir("archive/annotations")
def parse_xml(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
bbox = [[int(box.find(f"bndbox/{i}").text) for i in ["xmin", "ymin", "xmax", "ymax"]] for box in root.iter("object")]
labels = [2 if box.find("name").text == "with_mask" else 1 for box in root.iter("object")]
return bbox, labels
for i, anno in enumerate(annotation_file_list):
xml_path = "archive/annotations/" + anno
bbox, labels = parse_xml(xml_path)
new_file_name = anno.strip().split(".")[0] + ".txt"
new_file_path = "archive/labels/" + new_file_name
fw = open(new_file_path, "w")
for j, label in enumerate(labels):
x1, y1, x2, y2 = bbox[j]
s = str(label) + " " + str(x1) + " " + str(y1) + " " + str(x2) + " " + str(y2) + "\n"
fw.write(s)
fw.close()
最终做成的数据格式变成一个 txt 的文件,格式为:label x1 y1 x2 y2,注意,label 分别取了 1 表示未戴口罩,2 表示戴了口罩。同时,我们将数据集拆分成训练集和测试集两个部分。接下来通过 Dataset 类构造数据集,其实现代码如下:
class FacemaskDataset(Dataset):
def __init__(self, root_path):
self.root_path = root_path
self.images = sorted([root_path + "/train/" + i for i in os.listdir(root_path + "/train/")])
self.labels = sorted([root_path + "/train_labels/" + i for i in os.listdir(root_path + "/train_labels/")])
self.transform_img = transforms.Compose([transforms.ToTensor()])
def __getitem__(self, index):
img = Image.open(self.images[index]).convert("RGB")
bbox, labels = self._parse_label(self.labels[index])
target = {
"boxes": bbox,
"labels": labels,
"image_id": torch.tensor([index]),
"area": (bbox[:, 2] - bbox[:, 0]) * (bbox[:, 3] - bbox[:, 1]),
"iscrowd": torch.zeros(len(bbox), dtype=torch.int64)
}
return self.transform_img(img), target
def _parse_label(self, label_file):
bbox = []
labels = []
f = open(label_file)
for line in f.readlines():
bbox_i = []
lines = line.strip().split(" ")
labels.append(int(lines[0]))
for i in range(1, len(lines)):
bbox_i.append(int(lines[i]))
bbox.append(bbox_i)
bbox = torch.tensor(bbox, dtype=torch.float32)
labels = torch.tensor(labels, dtype=torch.int64)
return bbox, labels
def __len__(self):
return len(self.images)
此处有两个注意点:第一,对于图片,无需做 resize 的操作,因为在 Faster R-CNN 的代码中还会对其进行 resize 的操作,具体的操作在 GeneralizedRCNNTransform 类中。
第二个注意点事在 target 的构造部分,使用了 dict 的编排方式,这是因为在后续 resize 等一系列的操作中,会根据不同的字段找到对应的值,进行一些变换,具体的格式也可以参考[4]。
2.2. 搭建模型
因为是使用 TorchVision 中的实现方式,这里选用 fasterrcnn_resnet50_fpn,其完整的模型的代码如下:
model = fasterrcnn_resnet50_fpn(weights=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes=3)
model = model.to(device)
因为预训练模型的类别数与当前我们的数据集的类别个数不一致,因此要修改预测模型的数据个数。从上面数据集部分可以看到,实际上是 2 个类别,分别为戴口罩和未戴口罩,这里的 num_classes 参数是 3,这是因为还有一个隐藏的类别是背景。通过 summary() 函数查看网络结构,如下:
==============================================================================================================
Layer (type:depth-idx) Output Shape Param #
==============================================================================================================
FasterRCNNModel -- --
├─FasterRCNN: 1-1 [100, 4] --
│ └─GeneralizedRCNNTransform: 2-1 [1, 3, 800, 800] --
│ └─BackboneWithFPN: 2-2 [1, 256, 13, 13] --
│ │ └─IntermediateLayerGetter: 3-1 [1, 2048, 25, 25] 23,454,912
│ │ └─FeaturePyramidNetwork: 3-2 [1, 256, 13, 13] 3,344,384
│ └─RegionProposalNetwork: 2-3 [1000, 4] --
│ │ └─RPNHead: 3-3 [1, 3, 200, 200] 593,935
│ │ └─AnchorGenerator: 3-4 [159882, 4] --
│ └─RoIHeads: 2-4 [100, 4] --
│ │ └─MultiScaleRoIAlign: 3-5 [1000, 256, 7, 7] --
│ │ └─TwoMLPHead: 3-6 [1000, 1024] 13,895,680
│ │ └─FastRCNNPredictor: 3-7 [1000, 3] 15,375
==============================================================================================================
Total params: 41,304,286
Trainable params: 41,081,886
Non-trainable params: 222,400
Total mult-adds (G): 133.97
==============================================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 1483.73
Params size (MB): 165.22
Estimated Total Size (MB): 1649.54
==============================================================================================================
2.3. 损失函数
在 fasterrcnn_resnet50_fpn 中,有四个损失函数,在训练模式 model.train() 下,通过 print 直接打印 model 的输出 outputs = model(images, targets) 就可以得到所有的损失,结果如下:
{
'loss_classifier': tensor(1.4224, device='cuda:0', grad_fn=<NllLossBackward0>),
'loss_box_reg': tensor(0.1402, device='cuda:0', grad_fn=<DivBackward0>),
'loss_objectness': tensor(0.1346, device='cuda:0', grad_fn=<BinaryCrossEntropyWithLogitsBackward0>),
'loss_rpn_box_reg': tensor(0.0372, device='cuda:0', grad_fn=<DivBackward0>)
}
这里有四个损失函数:
- loss_classifier:整个 Faster R-CNN 对候选框的分类损失;
- loss_box_reg:整个 Faster R-CNN 对候选框的回归损失;
- loss_objectness:RPN 模块对于候选框是否是背景的分类损失;
- loss_rpn_box_reg:RPN 模块对于候选框的回归损失。
这四个损失通过线性组合在一起:
此处一般设置,代码如下:
outputs = model(images, targets)
optimizer.zero_grad()
print(f"train->outputs: {outputs}")
loss = sum(loss for loss in outputs.values())
2.4. 模型训练
模型训练的代码如下:
def train(self):
# 1. 加载数据,拆分训练集和验证集
train_dataset = FacemaskDataset(self.WORKING_DIR)
generator = torch.Generator().manual_seed(25)
train_dataset, val_dataset = random_split(train_dataset, [0.8, 0.2], generator=generator)
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cuda":
num_workers = torch.cuda.device_count() * 4
BATCH_SIZE = 8
train_dataloader = DataLoader(dataset=train_dataset,
num_workers=num_workers,
pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True,
collate_fn=self.collate_fn)
val_dataloader = DataLoader(dataset=val_dataset,
num_workers=num_workers,
pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True,
collate_fn=self.collate_fn)
# 2. 定义模型
model = fasterrcnn_resnet50_fpn(weights=True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes=3)
model = model.to(device)
# INFO: 设计模型参数
optimizer = optim.SGD([p for p in model.parameters() if p.requires_grad], lr=0.001, momentum=0.95, weight_decay=0.05)
EPOCHS = 40
train_losses = []
val_losses = []
best_val = float('-inf')
for epoch in tqdm(range(EPOCHS), desc="EPOCHS", leave=True):
model.train()
train_running_loss = 0
for idx, images_targets in enumerate(tqdm(train_dataloader, desc="Training", leave=True)):
images = [image.to(device) for image in images_targets[0]]
targets = [{k: v.to(device) for k, v in target.items()} for target in images_targets[1]]
outputs = model(images, targets)
optimizer.zero_grad()
# print(f"train->outputs: {outputs}")
loss = sum(loss for loss in outputs.values())
train_running_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = train_running_loss/(idx + 1)
train_losses.append(train_loss)
val_score = self.custom_evaluate(model, val_dataloader, device)
print(f"val_score: {val_score}")
if val_score["mAP"] > best_val:
best_val = val_score["mAP"]
torch.save(model.state_dict(), 'best_fasterrcnn.pth')
# INFO: 记录
EPOCHS_plot = []
train_losses_plot = []
val_losses_plot = []
for i in range(0, EPOCHS, 5):
EPOCHS_plot.append(i)
train_losses_plot.append(train_losses[i])
print(f"EPOCHS_plot: {EPOCHS_plot}")
print(f"train_losses_plot: {train_losses_plot}")
plot_losses(EPOCHS_plot, train_losses_plot, val_losses_plot, "fasterrcnn_train_val_losses.jpg")
请注意,在 DataLoader 函数中重新定义了 collate_fn 函数,其定义的代码如下:
def collate_fn(self, batch):
return tuple(zip(*batch))
其主要的原因是图像未经过 resize,collate_fn 默认会将数据打包成 batch,但是不是同样大小的数据无法打包,使用上述自定义的方式,直接以 tuple 返回训练数据。
在验证集上,我们定义了 mAP 的计算,其具体的代码如下:
def custom_evaluate(self, model, dataloader, device, num_classes=3, iou_threshold=0.5):
model.eval()
all_preds = []
all_targets = []
# 1. 数据收集阶段
with torch.no_grad():
for images, targets in dataloader:
images = [img.to(device) for img in images]
batch_preds = model(images) # 模型输出格式: List[Dict{boxes, labels, scores}]
# 转换预测结果为统一格式 [image_id, class, conf, x1, y1, x2, y2]
for img_idx, pred in enumerate(batch_preds):
img_id = targets[img_idx]['image_id'].item()
for box, label, score in zip(pred['boxes'], pred['labels'], pred['scores']):
all_preds.append([img_id, label.item(), score.item(), *box.cpu().tolist()])
# 转换真实标签为统一格式 [image_id, class, x1, y1, x2, y2]
for target in targets:
img_id = target['image_id'].item()
for box, label in zip(target['boxes'], target['labels']):
all_targets.append([img_id, label.item(), *box.cpu().tolist()])
# 2. 按类别分组
class_preds = defaultdict(list)
class_targets = defaultdict(list)
for pred in all_preds:
class_preds[pred[1]].append(pred)
for target in all_targets:
class_targets[target[1]].append(target)
# 3. 逐类别计算AP
aps = []
for class_id in range(num_classes):
preds = sorted(class_preds.get(class_id, []), key=lambda x: x[2], reverse=True) # 按置信度排序
targets = [t[2:] for t in class_targets.get(class_id, [])] # 提取坐标
tp = np.zeros(len(preds))
fp = np.zeros(len(preds))
gt_matched = defaultdict(set) # 记录已匹配的真实框
# 4. IoU匹配
for pred_idx, pred in enumerate(preds):
img_id = pred[0]
pred_box = pred[3:]
max_iou = 0.0
best_gt_idx = -1
# 获取同图像同类别真实框
img_targets = [t for t in class_targets[class_id] if t[0] == img_id]
for gt_idx, gt_box in enumerate(img_targets):
if gt_idx in gt_matched[img_id]:
continue # 已匹配的框跳过
iou = calculate_iou(pred_box, gt_box[2:]) # 计算IoU
if iou > max_iou and iou >= iou_threshold:
max_iou = iou
best_gt_idx = gt_idx
# 标记TP/FP
if best_gt_idx != -1:
tp[pred_idx] = 1
gt_matched[img_id].add(best_gt_idx)
else:
fp[pred_idx] = 1
# 5. 计算PR曲线
tp_cum = np.cumsum(tp)
fp_cum = np.cumsum(fp)
recalls = tp_cum / (len(targets) + 1e-6)
precisions = tp_cum / (tp_cum + fp_cum + 1e-6)
# 6. VOC 11点插值法计算AP
ap = 0.0
for t in np.arange(0, 1.1, 0.1):
mask = recalls >= t
if np.sum(mask) == 0:
p = 0
else:
p = np.max(precisions[mask])
ap += p / 11
aps.append(ap)
# 7. 计算全局指标
mAP = np.mean(aps) if aps else 0.0
final_recall = np.sum([len(v) for v in class_targets.values()]) / (len(all_targets) + 1e-6)
return {"mAP": mAP, "Recall": final_recall}
2.5. 模型预测
模型推理就是加载保存好的模型,并对新的数据预测,代码如下:
def predict(self, img, model_path, score=0.5):
transform_img = transforms.Compose([transforms.ToTensor()])
device = "cuda" if torch.cuda.is_available() else "cpu"
model = fasterrcnn_resnet50_fpn()
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes=3)
model = model.to(device)
model.load_state_dict(torch.load(model_path,
map_location=torch.device(device),
weights_only=True))
# 开始推理
model.eval()
with torch.inference_mode():
tensor_image = transform_img(img)
tensor_image = tensor_image.float().to(device)
pred = model(tensor_image.unsqueeze(0))
final_ans = []
# 解析出结果
for i in range(len(pred)):
box_res = pred[i]["boxes"].long().tolist()
print(f"box_res: {box_res}")
label_res = pred[i]["labels"].tolist()
print(f"label_res: {label_res}")
score_res = pred[i]["scores"].tolist()
print(f"score_res: {score_res}")
for j, label in enumerate(label_res):
if score_res[j] >= score:
ans = {}
ans["box"] = box_res[j]
ans["label"] = label
ans["score"] = score_res[j]
final_ans.append(ans)
return final_ans
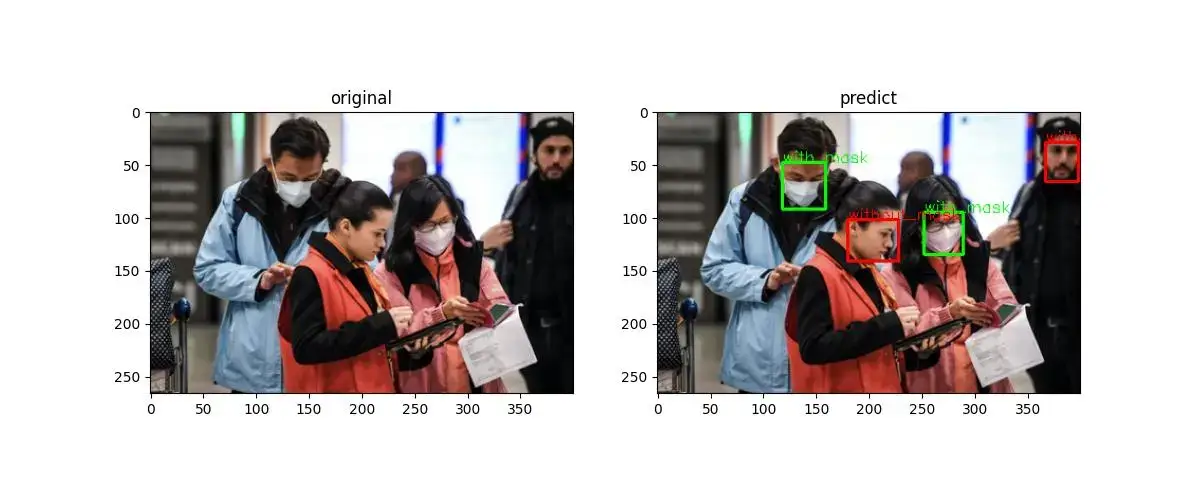
最终在测试数据上的表现如下:
3. 总结
文章主要是基于 TorchVision 中的 fasterrcnn_resnet50_fpn 模型,在新的数据集上 Finetune,完成基本的 Fast R-CNN 在口罩检测任务上的实践,这其中只是对 Faster R-CNN 的原理有粗略的涉及,要想理解其中的具体过程,还需要对其源代码做详细的理解。
参考文献
[1] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28.
[3] https://www.kaggle.com/datasets/andrewmvd/face-mask-detection/data
[4] https://docs.pytorch.org/tutorials/intermediate/torchvision_tutorial.html